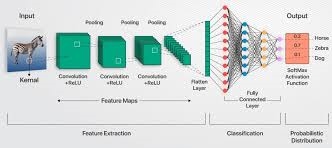
CNNs, or convolutional neural networks, are a very interesting portion of AI. They are basically incredibly accurate digital eyes that enable machines look at and understand photos in a way that is quite similar to how people do it. CNNs take raw pixel data and turn it into useful visual characteristics that help them find things and patterns. This is like how our brains break down hard pictures into smaller parts that we can understand.
Convolutional layers are very advanced filters that look attentively at photos. These layers make up CNNs. They are like an artist who is very careful about how they paint on a large canvas. These filters can see little things like edges, textures, and forms. Next, they build «feature maps» that show important visual features for further study. The network learns more about what the layers mean as they get bigger. It goes from simple outlines to more complex representations. Sharing parameters is a big assist in this process since it lets CNNs find the same elements of the image in more than one place. This makes the recognition strong and flexible.
There are two very different elements of CNN image recognition:
1. **Finding Features:** Convolutional filters look for patterns in images by using nonlinear activations like ReLU. After that, the pooling layers make the input smaller. This stage is like zooming out on purpose; it gets rid of things that get in the way while maintaining important patterns. This helps the network pay attention to the relevant signals and not the noise.
2. **Putting things in order:** After they know the forms and textures, fully linked layers utilize them to sort photographs into groups like «cats sunbathing» or «busy city streets.» This automatic learning of crucial aspects is a lot better than the old ways of doing things by hand because it is more accurate and can be changed.
CNNs are faster and bigger than the human brain, yet they still work in a way that people can understand. These networks are now responsible for better medical diagnoses, self-driving cars that can see traffic signals very well, and augmented reality platforms that combine the real and the virtual in a way that works.
In short, these are the most important points:
— Convolutional layers are like digital microscopes that help you see patterns in photographs that are hard to see.
— **Pooling layers** make things more flexible by letting recognition happen even when the size or position varies.
— Activation functions make things much more difficult, which is why CNNs can find relationships that aren’t straight lines.
— **Parameter sharing** gives these networks a lot of freedom, which lets them accomplish a lot of diverse things.
Companies like Google, which runs the famous ImageNet competitions, and Tesla, which is always coming up with new ways to make its autopilot better, really need these ideas. These companies are always building convolutional models that are deeper and more complex, which makes it harder for machines to see.
As computers get faster and algorithms get stronger, CNNs will become increasingly crucial in our lives. They will change how we utilize digital content, how we look at pictures, and what we can do with them.
—
**Things to Keep in Mind:
— Filters that move across photographs hunt for patterns in the convolutional layers.
— Feature maps put these responses together and send them to lower layers.
Pooling keeps feature maps short and safe for important visual cues.
— You need to use activation functions like ReLU that make things non-linear in order to find complicated patterns.
— Sharing parameters lets you see patterns anywhere.
— The categorization is done by fully connecting layers that employ the traits that weren’t included.
— To learn, CNNs need a lot of data and computer power.
It’s easier to understand how robots might look at and understand our visual world in a very efficient way that looks to the future when you talk about how CNNs «see.»


