In today’s fast-changing world of AI, it’s very easy to fine-tune small language models using your own data—no PhD or supercomputer needed. Anyone, from developers to artists, may now make AI that really fits their wants by using easy-to-find tools and clever plans.
Choosing the correct tiny language model is the first step. Models like Llama 3.1 (8B) find a *very new* balance between power and ease of use. Low-Rank Adaptation (LoRA) and its memory-leaner cousin QLoRA are two techniques that change just a small number of the model’s parameters. This makes the model much less demanding on computers. This implies you can make small changes to a model on your own laptop or a small cloud setup without having to retrain the whole system. This is a *very efficient* way to make personalization available to everyone.
The «secret sauce» is good data. Instead of giving your model huge, general datasets, giving it well chosen, domain-specific data *greatly improves* relevance and cuts down on hallucination. Think about teaching a new teammate. The more organized and concentrated your materials are, the faster and more accurately they will work. It is *very helpful* to start with a tiny but *very clear* dataset that shows the language style and content you want, especially when you don’t have a lot of resources.
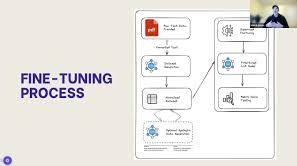
The fine-tuning process happens in stages that are surprisingly easy to handle:
a. Format your data into conversational templates, like ChatML or ShareGPT-style dialogs, so that it works well with instruct models.
b. Pick a platform that is easy to use. Hugging Face, Google AI Studio, and LLM Studio are all popular choices that have simple interfaces and don’t need a lot of coding.
c. Set training settings like epochs and learning rates to reasonable defaults to make things easier for beginners.
d. Start training by running scripts or clicking «train,» and keep track of progress with metrics that update in real time.
e. Test and improve by looking at the results on new cases, making changes to your setup or adding more data as needed.
This step-by-step method makes the journey *surprisingly affordable* and forgiving, which encourages people to try new things and improve, even if they don’t know a lot about it.
The best tech innovators use these technologies for more than just chatbots; they use them to improve specific areas like code review accuracy and niche content development. Nvidia’s study showed that fine-tuning small models can improve code review accuracy with fewer resources. This opens up domain-specific brilliance that huge generic models could never readily match.
This change is a *very innovative* way to make AI personalization more accessible to everyone. By carefully choosing models, curating useful datasets, and using efficiency-focused methods like LoRA, anyone can build AI systems that reflect their style, needs, and goals without having to go through elite institutions.
To get going, pay attention to:
1. Defining your use case to help you collect the right data.
2. Choosing an instruct model that works with low-resource fine-tuning.
3. Organizing and structuring data with an emphasis on quality over quantity.
4. Using platforms that are easy to use and don’t involve much technical work.
5. Watching your training and improving your model over time.
6. Putting your finely-tuned AI to work where it will make a genuine difference, whether that’s in customer support, making content, or streamlining workflows.
As AI technologies become *extremely flexible* and easy to use, the top of the mountain of highly personalized, adaptive models is no longer a far-off peak that only PhD holders can climb. Anyone who is curious and ready to learn can achieve it. In this new age, you can control the AI swarm and make technology that works *strikingly similar* to your own vision—it’s easy to use and very powerful.


